
Dans une avancée révolutionnaire, Google Chrome permet désormais aux utilisateurs de copier et rechercher du texte dans des PDF scannés. Cette fonctionnalité améliore considérablement la lisibilité et transforme la manière dont nous interagissons avec les documents numériques, facilitant l’accès à l’information pour tous.

Google Chrome a récemment mis en place une fonctionnalité qui permet aux utilisateurs de copier du texte à partir de fichiers PDF scannés. Cette amélioration, attendue depuis longtemps, s’avère très bénéfique.
Un des principaux problèmes rencontrés en ouvrant un PDF dans Chrome est la possibilité que le document original ait été numérisé au lieu d’être créé de manière numérique. Dans ce cas, le texte devient invisible pour le lecteur PDF de Chrome, ce qui rend impossible sa sélection et sa copie. De plus, la fonction de recherche de pages de Chrome n’est pas utile non plus.
Avec une mise à jour récente, Google a renforcé la capacité du lecteur PDF. Désormais, Chrome peut identifier le texte dans les documents scannés, ce qui permet de le copier, de le sélectionner, et de le rechercher à l’aide de « Ctrl + F ».
Cette fonctionnalité a d’abord été introduite dans la version bêta de Chrome, mais elle semble maintenant être accessible à un plus grand nombre d’utilisateurs. Cet outil agit comme une ressource pour ceux qui souhaitent retrouver du texte dans des documents, même si ceux-ci ont été importés de manière optique. Un fichier numérique conservera cette signature, permettant à Chrome de détecter le texte, tandis que les fichiers scannés ne possédaient pas cette signature, les rendant illisibles pour le lecteur PDF de Chrome.
La fonctionnalité fonctionne exactement de la même manière que pour un PDF normal lors de la copie de texte dans Chrome. La mise en surbrillance du texte permet de le copier et la recherche sur la page affichera des résultats correspondant à la phrase entrée. Il n’y a pas de différence notoire dans l’affichage entre un document et un autre.
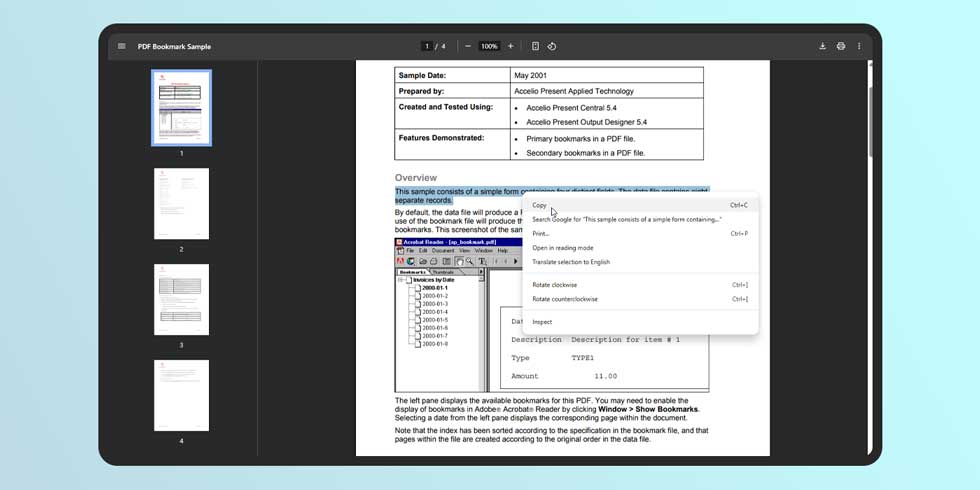
Il était seulement logique que Chrome introduise cette fonctionnalité, surtout compte tenu du rôle prépondérant de Google Lens dans le navigateur. Bien que la détection du texte ait été une fonction existante, elle ne semblait pas aussi intégrée que celle-ci.
Plus sur Chrome :
Pour plus d’informations, consultez le site de support officiel de Google.
Qu’est-ce que la nouvelle fonctionnalité de Google Chrome pour les PDF scannés ?
Google Chrome permet désormais aux utilisateurs de copier du texte à partir de PDF scannés, rendant les documents plus accessibles.
Comment fonctionne cette fonctionnalité ?
La fonctionnalité permet de sélectionner, copier et rechercher du texte dans les PDF scannés en utilisant « Ctrl + F », comme pour les PDF numériques.
Pourquoi était-ce un problème auparavant ?
Avant cette mise à jour, le texte dans les PDF scannés n’était pas détectable par le lecteur PDF de Chrome, rendant la recherche et la copie impossibles.
Quand cette fonctionnalité a-t-elle été introduite ?
Elle a été initialement introduite dans la version bêta de Chrome, mais est maintenant disponible pour un plus grand nombre d’utilisateurs.